ph (+46) 8 674 75 47
mob. ph. (+46) 70 568 13 59
fax. (+46) 8 703 90 25
Email: hercules@dsv.su.se
The Surface generator is a DCG surface grammar (File: grammar) where
the terminals are the lexical items (File: lexicon)
The Deep generator consists of a number of modules for carrying out
the
aggregation.
Syntactic aggregation (File: aggrules)
Bounded Lexical aggregation (File: bl_rules)
Unbounded Lexical aggregation (File: ub_rules)
Pronominalisation (File: pronoun)
The control or top level loop of ASTROGEN is the (File: tools)
Remaining files to talk about later.
:- reconsult(op).
:- reconsult(library).
:- reconsult(sorting).
:- reconsult(permut).
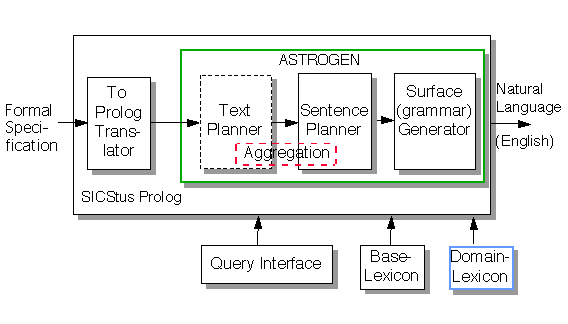
The modules within the green border (see Figure 1) are contained in the ASTROGEN system. To adapt the ASTROGEN system to any other system a translation has to be made from the other systems representation to ASTROGEN's f-structures, There is a basic lexicon avalaible within ASTROGEN but for domain specific terms a new one has to be written. ASTROGEN does not contain a real text planner but a sentence planner which is specialized in aggregation .
Copyright Hercules Dalianis, ASTROGEN are not allowed to be used in commercial applications without a licence.
(Totally 15 files )
?- consult(astrogen)
Loading ASTROGEN...
ASTROGEN loaded!
?-
paraphrase(+IN) where IN is an input of frametype, the answer is an NL string
paraphrase(+IN, -NL) where IN is an input of frametype, the answer is a list of NL
Input IN = f(T,P,Arg1,Arg2,Arg3)
IN can have optional numbers of arguments Arg.
T = {past, pres, fut} is the time predicates
P is some sort of predicate, (relation) verb E.g lexical items are, have, dials, see (File: lexicon)
Arg1, Arg2, and Arg3 are subjects (entitities) nouns, pronouns, E.g.
lexical items
John, subscriber, see (File: lexicon).
/* This does not work
Arg3 can be a cardinality relation represented by arg3 = card(entity,[n,m])).
E.g. f(pres,poss,person,card(child,[1,3])).
*/
IN can have the structure IN1 & IN2 & .... INn
Deep generation top level predicate is
deep(+IN,-OUT)
Deep generation is controled by the following switches
John is a subscriber and
Mary is a subscriber and
John is busy and
Mary is idle.
yes
?-
normal/0 switches off all aggregation rules
user_help/0. tells which the switches are
?- user_help.
These are all the switches for aggregation
One can also use set(SWITCH(no)) to remove it
subject_pred
predicate_do
subject
predicate
sym_rel
pronoun
bound_lex
un_bound_lex
clause_comma
canned_text
canned_example
yes
?-
predicate_do/0 switches on predicate and direct object aggregation
predicate/0 switches on predicate aggregation
sym_rel/0 switches on symmetric relation aggregation
?- all_rules.
yes
?- paraphrase(f(pres,isa,john,subscriber) & f(pres,isa,mary,subscriber) & f(pres,state,john,busy) & f(pres,state,mary,idle) ).
John and Mary are subscribers and
John is busy and
Mary is idle.
yes
un_bound_lex/0 switches on unbounded lexical aggregation
surface(+IN, -NL).
IN = (T,P,Arg1,Arg2,Arg3) a frame structure which might be aggregated.
NL is a natural language list.
?- paraphrase(f(pres,
work_action,john, monday) & f(pres, work_action,john,
tuesday) & f(pres, work_action,john, wednesday) &
f(pres,work_action,john,thursday) & f(pres, work_action,john,
friday)).
John works on Monday, Tuesday,
Wednesday, Thursday and Friday.
yes
?- bound_lex.
yes
?- paraphrase(f(pres,
work_action,john, monday) & f(pres,
work_action,john, tuesday) & f(pres, work_action,john, wednesday)
& f(pres,work_action,john,thursday) & f(pres,
work_action,john, friday)).
John works on weekdays.
yes?-
E.g.
?- normal.
yes
?- predicate_do.
yes
?- pronoun.
yes
?- paraphrase(f(pres,isa,john,subscriber) &
f(pres,isa,mary,subscriber)
&
f(pres,state,john,idle) & f(pres,state,mary,idle) ).
John and Mary are subscribers and
they are idle.
yes
I.e. instead of generating 'and' between clauses f-structures commas are generated.
?- clause_comma.
yes
?- paraphrase(f(pres,isa,john,subscriber) & f(pres,isa,mary,subscriber) & f(pres,state,john,busy) & f(pres,state,mary,idle)).
<>John and Mary are subscribers.These two above predicates switches on hybrid textgeneration.
Hybrid text generation is mixture of normal text generation (from
f-structures)
and canned text generation
(already ready text)
To perform hybrid textgeneration one needs to create an extra
predicate.
Canned text cannot be processed by the paraphrase/0 predicate.
I.e. information which is not availables as f-structure but as canned text.
Below the clause syntax
f(pres, Predicate, Subject, Object).
The clauses can now be ordered according to the keys Predicate(key 1), Subject (key 2), and Object (key 3), by giving them various priorities. The ordering rule order the clauses in a text plan according to the weights of that rule. The weights correspond to the predicate, subject and object of the clause. E.g. the 3,2,1 ordering means that the predicate has the highest priority to be ordered followed by the subject and finally the object.
Different sorting order could for example be 1,3,2 or 2,1,3 or 1,3,2.
e.g. (File: tools)
:- sort(1,2,3)
:- sort(2,1,3)
:- sort( 1,3,2).
to remove all sorting
:- sort(n,n,n).
?- all_rules.
yes
?- sort(1,2,3).
yes
?- paraphrase(f(pres,isa,john,subscriber) & f(pres,isa,mary,subscriber) & f(pres,state,john,idle) & f(pres,state,mary,busy) ).
john and mary are subscribers and
john is idle and
mary is busy.
yes
?- sort(2,1,3).
yes
?- paraphrase(f(pres,isa,john,subscriber) &
f(pres,isa,mary,subscriber)
&
f(pres,state,john,idle) & f(pres,state,mary,busy) ).
john is idle and
mary is busy and
john and mary are subscribers.
yes
?- sort( 1,3,2).
yes
?- paraphrase(f(pres,isa,john,subscriber) &
f(pres,isa,mary,subscriber)
&
f(pres,state,john,idle) & f(pres,state,mary,busy) ).
john and mary are subscribers and
mary is busy and
john is idle.
yes
For SICStus Prolog do not forget to declare all new predicates which
are defined in many different files as multifile.
E.g. :- multifile noun/5, verb/5, adj/4,propernoun/5,conj/3,cue/3.
See file (File:lexicon) to see the syntax of the lexicon.
Add two new Prolog clauses (one for singular and for plural form) to add the noun product
noun(sing,neut,product) --> [product].
noun(plur,neut,product) --> [products].
the second argument is the gender
mask = maskulinum, fem = femininum and neut = neutrum
Then reconsult the (File: lexicon)
Add four new Prolog clauses to add the verb belong to (singular,
plural, past, present and future tense)
verb(pres,sing,belong_rel) --> [belongs,to].
verb(pres,plur,belong_rel) --> [belong,to].
verb(past,_,belong_rel) --> [belonged,to].
verb(fut,_,belong_rel) --> [will, belong,to].
These markers must be integers if one put the same number on two different instance then they are the same. If one put different numbers they are different instances.
This feature can be used for other purposes as well. To control the
generation of sentences like the other subscriber This is not
implemented
yet.
These work partly, there is a newly introduced bug
?-
paraphrase(f(pres,poss/1,john,book/1)&f(pres,poss/2,mary,book/2)).
John and Maryhave a book each.
yes
?-
paraphrase(f(pres,poss/1,john,book/1)&f(pres,poss/1,mary,book/1)).
John and Maryhave a book together.
yes
?-
paraphrase(f(pres,poss/1,john,book/1)&f(pres,poss/2,mary,pen/1)).
John and Maryhave a book and a pen respectively.
yes
?- paraphrase(f(pres,poss/1,john,f(pres,state,car,red))& f(pres,poss/1,mary,f(pres,state,car,red))).?- normal.
yes
?- paraphrase(f(pres,poss,john,ring_tone) &
f(pres,call_action,
[john],mary) &
f(pres,poss, mary,ring_signal)).
John has a ringtone and
Calls Mary and
Mary has a ringsignal.
yes
(Not ready yet)